Cross Layer SLA Management in Big Data Application Workflows
Cloud computing has transformed people’s perception of how Internet-based applications can be deployed in datacenters and offered to users in a pay-as-you-go model. Despite the growing adoption of cloud datacenters, challenges related to big data application management still exist. One important research challenge is selecting configurations of resources as infrastructure-as-a-service (IaaS) and platform-as-a-service (PaaS) layers such that big data application-specific service-level agreement goals (such as minimizing event-detection and decision-making delays, maximizing application and data availability, and maximizing the number of alerts sent per second) are constantly achieved for big data application workflows.
To simplify understanding of the cross-layer resource configuration selection problem, consider a social-network-driven stock recommendation big data application deployed on an AWS datacenter, as illustrated in Figure 1.
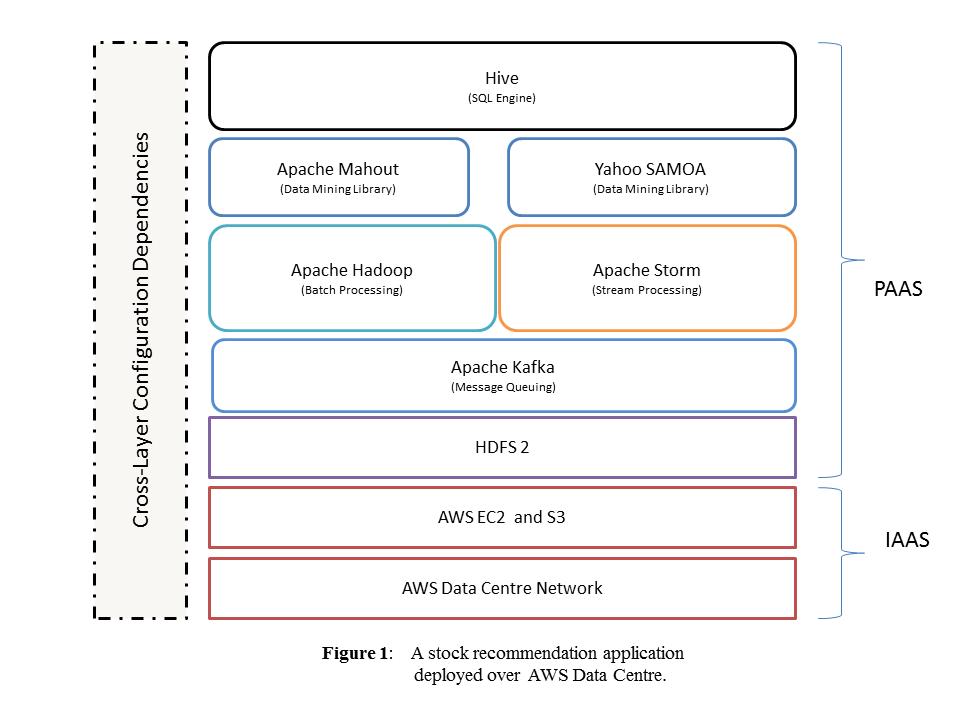
This application workflow needs to process both historical and real-time data, hence its application architecture consists of multiple and heterogeneous big data processing frameworks. Therefore, the application combines streaming freeform text data from the Twitter API with historical tweets (available via Twitter Firehose) stored in Amazon Simple Storage Service (S3) hardware resources. In the example in Figure 1,
• Apache Kafka is deployed as a high-throughput message-queuing framework;
• Apache Storm is deployed as a stream-processing framework that in turn exploits Yahoo Scalable Advanced Massive Online Analysis (SAMOA) as a data mining framework for classifying groups of tweets relevant to a particular stock;
• Apache Hadoop is deployed for processing historical tweets;
• Apache Mahout, which is hosted within the Apache Hadoop runtime environment, implements a Bayesian classifier algorithm for tweet grouping and classification; and
• the output of both batch and stream analytics subsystems is written to the Hadoop Distributed File System (HDFS).
To query the analytics result (for example, the top K most promising stock portfolios), Apache Hive is deployed to support search queries in Standard Query Language (SQL) format.
As Figure 1 shows, there are two application management layers in a big data application platform. The first is a big data processing or PaaS framework (Apache Hadoop, Apache Storm, Apache Mahout, and so on) layer that implements software-based data processing primitives (for example, batch processing by Apache Hadoop or stream processing by Apache Storm). In the second IaaS layer, cloud-based hardware or IaaS resources (for example, CPU, storage, and network) provide hardware resource capacity to the higher-level PaaS frameworks.
The hard challenge is determining the optimal approach “to automatically select IaaS resource and big data processing framework configurations such that the anticipated application-level performance SLA constraints (for example, minimize event-detection and decision-making delays, maximize application and data availability, and maximize number of alerts sent per second) are constantly achieved, while maximizing cloud datacenter CPU utilization, CPU throughput, network throughput, storage throughput, and energy efficiency.
The vast configuration diversity among the available cloud resources and big data processing frameworks makes it difficult for application administrators to select configurations or even determine a valid background for their decisions. Consequently, allocating IaaS-level cloud resources to PaaS-level big data processing frameworks is no longer a traditional time-minimization or resource-maximization problem but involves additional simultaneous objectives and configuration dependencies across multiple IaaS resources and big data processing frameworks. These include, but aren’t limited to,
- maximizing classification accuracy for Apache Mahout,
- minimizing response time for map and reduce tasks in Apache Hadoop,
- minimizing stream processing latency in Apache Storm,
- maximizing network throughput for HDFS,
- maximizing CPU resource utilization, and
- minimizing energy consumption for the datacenter.
Existing big data application orchestration platforms (Apache YARN, Mesos, and Apache Spark) are designed for homogeneous clusters of IaaS resources. These platforms expect application administrators to determine the number and configuration of allocated IaaS resource types and provide appropriate configuration parameters for each IaaS resource type and big data processing framework for running their analytics tasks. Branded price calculators, available from public cloud providers such as AWS (http://calculator.s3.amazonaws.com/index.html) and Azure (http://www.windowsazure.com/en-us/pricing/calculator) and academic projects such as Cloudrado (www.cloudorado.com), allow comparison of IaaS resource leasing costs. However, these calculators can’t recommend or compare configurations across big data processing frameworks and hardware resources while ensuring application-level SLAs (such as minimizing event-detection delay).
**Copyright on my articles is held by respective publishers. They are posted here for educational purpose only. If you want to use them for commercial purpose, please consult copyright owners!
Further Reading
- R. Ranjan, J. Kołodziej, L. Wang, and A. Zomaya, “The Cross-Layer Cloud Resource Configuration Selection Challenge in the Big Data Era,” IEEE Cloud Computing, BlueSkies Column, IEEE Computer Society. (Accepted June 2015, reviewed by Editorial Board, in press)
- X. Zeng, R. Ranjan, P. Strazdins, S. Garg, and L. Wang, “Cross-Layer SLA Management for Cloud-hosted Big Data Analytics Applications”, The 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, May 2015, IEEE Computer Society. [ERA A Ranked]
- Ranjan, “Streaming Big Data Processing in Datacenter Clouds”. IEEE Cloud Computing 1(1): 78-83 (2014)
- R. Ranjan, L. Wang, A. Zomaya, D. Georgakopoulos, X. Sun, and G. Wang, “Recent Advances in Autonomic Provisioning of Big Data Applications on Clouds,” IEEE Transactions on Cloud Computing, IEEE Computer Society Press. (Accepted May 2015, in press)
- K. Alhamazani, R. Ranjan, P. Jayaraman, K. Mitra, F. Rabhi, D. Georgakopulos, and L. Wang, “Cross-Layer Multi-Cloud Real-Time Application QoS Monitoring and Benchmarking As-a-Service Framework,” IEEE Transactions on Cloud Computing, IEEE Computer Society. (Accepted April 2015, in press)
- M. Zhang, R. Ranjan, M. Menzel, S. Nepal, P. Strazdins, and L. Wang, “A Cloud Infrastructure Service Recommendation Technique for Optimizing Real-time QoS provisioning Constraints“, IEEE Systems, IEEE Computer Society. [ISI Impact Factor 1.7] (Accepted April 2015, in press)
- L. Wang and R. Ranjan, “Processing Distributed Internet of Things Data in Clouds, ” IEEE Cloud Computing, BlueSkies Column, IEEE Computer Society. (Accepted March 2015, reviewed by Editorial Board)
- R. Ranjan, “Modeling and Simulation in Performance Optimization of Big Data Processing Frameworks,” IEEE Cloud Computing, Volume 1, Issue 4, BlueSkies Column, IEEE Computer Society. (reviewed by Editorial Board)
- R. Calheiros, E. Masoumi, R. Ranjan, R. Buyya, “Workload Prediction Using ARIMA Model and Its Impact on Cloud Applications’ QoS“, IEEE Transactions on Cloud Computing, IEEE Computer Society Press. (Accepted August 2014)
- A. Khoshkbarforoushhaa, A. Khosravianc, and R. Ranjan, “Elasticity Management of Streaming Data Analytics Flows on Clouds,” Journal of Computer System Sciences, Elsevier. [ISI Impact Factor 1.58, ERA A*] (Accepted November 2016, in press)
